|
|
|
|
|
|
|
Discussion: The data are available in the form of a pair of numbers for each vote. The first number is the precinct number; the second number is the candidate number. |
|
|
|
|
|
|
|
|
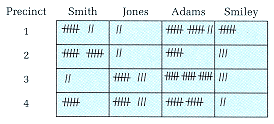
If we were doing the analysis by hand, our first task would be to go through the data, counting how many people in each precinct voted for each candidate. We would probably create a table with precincts down the side and candidates across the top. Each vote would be recorded as a hash mark in the appropriate column and row (see Figure 13-10). |
|
|
|
|
|
|
|
|
When all of the votes had been recorded, a sum of each column would tell us how many votes each candidate had received. A sum of each row would tell us how many people had voted in each precinct. |
|
|
|
|
|
|
|
|
As is so often the case, this by-hand algorithm can be used directly in our program. A two-dimensional array can be created where each component is a counter for the number of votes for a particular candidate in each precinct; that is, the value indexed by [2][1] would be the counter for the votes for candidate 1 in precinct 2. Well, not quite. C++ arrays are indexed beginning at 0, so the correct array component would be indexed by [1][0]. When we input a precinct number and candidate number, we must remember to subtract 1 from each before indexing into the array. Likewise, we must add 1 to an array index that represents a precinct number or candidate number before printing it out. |
|
|
|
 |
|
|
|
|
A two-dimensional array votes, where the rows represent precincts and the columns represent candidates |
|
|
|
|
|
|
|
|
A one-dimensional array of strings containing the names of the candidates, to be used for printing (see Figure 13-11). |
|
|
|
|
|
|
|
|
In the top-down design beginning on the following page, we use named constants NUM_PRECINCTS and NUM_CANDIDATES in place of the literal constants 4 and 4. |
|
|
|
|
|