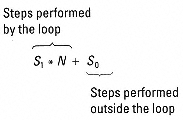|
|
|
|
|
steps. We define a step as any operation roughly equivalent in complexity to a comparison, an I/O operation, or an assignment. |
|
|
|
|
|
|
|
|
|
Given an algorithm with just a sequence of statements (no branches or loops), the number of steps performed is directly related to the number of statements. When we introduce branches, however, we make it possible to skip some statements in the algorithm. Branches allow us to subtract steps without physically removing them from the algorithm because only one branch is executed at a time. But because we always want to express work in terms of the worst-case scenario, we use the number of steps in the longest branch. |
|
|
|
|
|
|
|
|
|
Now consider the effect of a loop. If a loop repeats a sequence of 15 simple statements 10 times, it performs 150 steps. Loops allow us to multiply the work done in an algorithm without physically adding statements. |
|
|
|
|
|
|
|
|
|
Now that we have a measure for the work done in an algorithm, we can compare algorithms. For example, if Algorithm A always executes 3124 steps and Algorithm B always does the same task in 1321 steps, then we can say that Algorithm B is more efficientthat is, it takes fewer steps to accomplish the same task. |
|
|
|
|
|
|
|
|
|
If an algorithm always takes the same number of steps regardless of how many data values it processes, we say that it executes in constant time. Be careful: Constant time doesn't mean small; it means that the amount of work done does not depend on the number of data values. |
|
|
|
|
|
|
|
|
|
If a loop executes a fixed number of times, the work done is greater than the physical number of statements but is still constant. But what happens if the number of loop iterations can change from one run to the next? Suppose a data file contains N data values to be processed in a loop. If the loop reads and processes one value during each iteration, then the loop executesN iterations. The amount of work done thus depends on a variable, the number of data values. Algorithms that perform work directly proportional to the number of data values are said to execute in linear time. If we have a loop that executes N times, the number of steps to be executed is linearly dependent on N. |
|
|
|
|
|
|
|
|
|
Specifically, the work done by an algorithm with a data-dependent loop is |
|
|
|
|
|
|
|
|
|
|
where S1 is the number of steps in the loop body (a constant for a given loop), N is the number of iterations (a variable), and S0 is the number of steps outside the loop. (We can use this same formula for constant-time loops, but N would be a constant.) Notice that if N grows very large, the term S1 * N dominates the execution time. That is, S0 becomes an insignificant part of the total execution time. |
|
|
|
|
|
|
|
|
|
What about a data-dependent loop that contains a nested loop? The number of steps in the inner loop, S2, and the number of iterations performed by the inner loop, L, must be multiplied by the number of iterations in the outer loop: |
|
|
|
|